A journey into learning to extend Kubernetes - custom Controllers
Introduction to Kubernetes Controllers
As we know, Kubernetes (k8s) is a container orchestration project, and with it comes the concept of “self healing”. Some of the familiar units described in k8s, like deployments, have a “controller” that watches and reconciles (a function) that is constantly monitoring the observed state and comparing it with the desired state of the cluster, it will then reconcile deviations to ensure both match (in k8s this is happening continually - this is called a control loop). I have illustrated this below with a simple image from the k8s website. An example of this in todays world may be automated balance top up on a phone (pay-as-you-go yo).
A control loop is setting an alert (watcher), triggering the action to top up when your balance reaches a certain limit, the controller in this scenario charges the bank account you specify should be linked with the service and you never run out of credit.
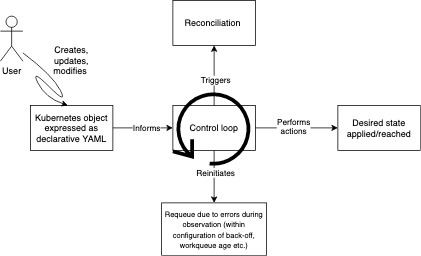
Where does an Operator fit into all of this?
An Operator is essentially a way to code human operational knowledge of performing certain actions, and having custom resource definitions that make use of a Controller to manage this for us, in an automated way. It knows how to perform these actions for specific or complex software (think configuration management of resources that are created as part of a deployment by the controller e.g. a Service listening on specific ports).
Important to note, not all Controllers are Operators*, but all Operators will have a Controller.
My plan for the “test-controller” repository linked further down in this post, I plan to expand a bit on it, or use one of the other frameworks to assist in helping to build some useful examples of both Controllers, and Operators :)
What are the building blocks of a controller?
I watched a fantastic talk by Marciej Szulik from RedHat on the topic - which I’ve included here and some of the things I took away from this were;
Control loops are the foundational component of the Controller, since that’s where the business logic is implemented Shared Informers should be used for the following reasons; Event handlers - add/update/delete Caching - a shared cache should be read from in order to increase efficiency, client side query and caching mechanism Listers syncHandlers - workqueue and processing of items
The Shared Informers model pushes events from the kube-apiserver to be caught by our Controller for use in our code or business logic.
Given that this is such a dynamic environment, there are also other frameworks which outline some building blocks, like the Kubernetes sig project controller-runtime which has a good example using the ‘/pkg/builder’, this is something I have looked at below also. The two main element in the builder example seem to be that you need a Manager (that needs to be started before a controller can be managed by it - which seems obvious on hindsight!) and a Controller. Of course, there are other frameworks out there and this is just one example.
Why would you even want to write a custom controller, anyway?
Custom Controllers (or Operators, too) are useful in scenarios that you want to automate or perform actions that is triggered by an event when observed. This kind of folds into Event-Driven architecture, which is another topic in itself, but thats how I see it.
This model allows you build programs that embody human knowledge, and takes the burden off of human operators performing manual tasks that have many steps. Let’s imagine an example, every morning you open the fridge to check the amount of milk you have left, you should always have 1 milk carton in the fridge at all times (regardless of the mm’s it has left), once empty you go to the shop and buy another milk carton and restock the fridge. This is the reconciliation, the Control loop is watching the amount of milk left, when empty, this is the trigger for the reconciliation. A bit of a contrived example aha!
A sample controller (based on that written by Joe Beda, for TGI Kubernetes)
The code for this Controller can be found here, it is a bit of a mash up between Joe Beda’s Controller from the live sessions of TGI Kubernetes, the playlist is here and the episode numbers are 007,008,009 thank you to Joe for those sessions! You can add more functions to make the Controller do more, that way you can just keep extending this example or replace Deployments with another object to watch :) I also used some of the concepts/code from the sample-controller, which is also a good primer for writing a basic Controller (although you might have to chop things out as I have done).
Some snippets of the important bits are below with a little explanation;
Firstly you need to define a Struct that creates the low-level Controller, parameterized by a Config and will also be used by the sharedIndexInformer.
type Controller struct {
deploymentGetter appsv1.DeploymentsGetter
deploymentLister appslisters.DeploymentLister
deploymentSynced cache.InformerSynced
queue workqueue.RateLimitingInterface
}
If you also wanted to be able to create/update/delete other objects, you would include the appropriate objects here, an example might be secretGetter corev1.SecretsGetter where secretGetter could be used as a method for our struct in later functions. This might look like func (c *Controller) getSecrets(ns string) (*[]corev1.Secret, error) { secrets, err := c.secretGetter.<something>...} which looks fairly familiar.
Moving on, to return a new Controller, we call our func NewController() with a couple of things. The kubernetes.Clientset is the interface through which we interact with the features that this group provides (there is a Client for each “group”, e.g. *appsv1). Below is the code for that element of the Controller program;
func NewController(kubeclient *kubernetes.Clientset, deploymentInformer appsinformers.DeploymentInformer) *Controller {
c := &Controller{
deploymentGetter: kubeclient.AppsV1(),
deploymentLister: deploymentInformer.Lister(),
deploymentSynced: deploymentInformer.Informer().HasSynced,
queue: workqueue.NewNamedRateLimitingQueue(workqueue.DefaultControllerRateLimiter(), "deploymentlister"),
}
Here we dereference Controller to assign the address of the variable “c” of type Controller, which is a struct, this means we should be able to work on Controller. I’ll stop here before I’ve walked through the entire program, so that will encourage anyone feeling overwhelmed that you can write your own if a novice like I can do it. :)
I am by no means a Golang expert, and I’m still early in my journey to understanding this comprehensively, so anything above should be taken accordingly!
The Controller (in action) behaves in a way I have not yet figured out because it is printing the Deployment twice when it sees the new annotation (where the arguments to these are oldObj, newObj), which could be due to the AddFunc: and UpdateFunc: both calling the function to get the deployments that match, respectively. Or it could be that there is no distinction between “Deployment” and “ReplicaSet” objects here, so both are printed (thoughts, so many thoughts). I put a couple of images below demonstrating the output you can expect if you print verbose/return deployment objects and format print the values (JSON blob).

If you see a lot of print statements “seen annotation”, I verified that it is only picking up our deployment in the default namespace (if that’s where you create it). However, you will see some periodic updates at an interval of 10 minutes due to the SharedIndexInformer (InformerFactory, in the main function) which also prints “seen annotation”, this is something I’m looking at :)
Common frameworks for extending Kubernetes functionality
So, writing Controllers from scratch is not really a feasible way to build them unless you need something that is highly customised, specific, and you need it to meet certain requirements (think rate limiting, timeouts during cache sync, retry time if cache is not synced, and other custom functions that might be specific to an application in your organisation). But there do exist some very nice frameworks which boilerplate most of the basic building blocks for you, these are;
KUDO - Not specifically for Controllers, but lets you write Operators in a declarative fashion, in everyones favourite markdown language... yaml :D
Operator-SDK - Higher level abstraction and boilerplate for Operators which uses the controller-runtime project
Kubebuilder - Similar to above, uses controller-runtime and provides higher level abstractions which make it easier to build controllers and custom resources
Kubebuilder - project setup, boilerplate and scaffolding
First, I would recommend heading over to the Kubebuilder site where the instructions and documentation for getting started are very good.
kubebuilder init --domain curious.af
A gotcha is that the project directory in your GOPATH ($GOPATH/src/project) must match the validation regex, I couldn’t figure out why when I supplied a “domain” that was valid it got rejected because I didn’t look closely enough at the error! (my fault).
Once you initialise a domain, this scaffolds out some of the yaml files needed to manage some of the API resources you’ll create later, as well as a Kustomize base. It’s not until the next stage when you are running kubebuilder create api that the custom resource definition and the
In another blog post, I will go through the thought process of designing a new controller (because I have realised I haven’t covered it here!!).
Ciao!