90 Degrees Starboard
Policy-based enforcement with Open Policy Agent
Edit: the policy that I was working on is now complete (there were a couple of edge cases) and can be found here
As I was watching TGI Kubernetes last week, someone asked a very interesting question that I thought would be interesting to explore. Does Starboard (by AquaSec) integrate with Open Policy Agent (OPA)? The answer is yes, you can use “kube-mgmt” to enforce policies based on that data (more on where it is stored, how it is accessed later in this post).
An overview of Starboard
Starboard is a container security tool with some great features, most of which resemble what if offered as part of the commercial tool, and while it’s still in Alpha is a really promising project that I’ve been meaning to try since Duffie Cooley demo’d it last week on TGI Kubernetes. Some of those features include;
- Hunting for common misconfigurations that attackers could use to compromise the cluster etc. (kube-hunter)
- Reporting on the Node compliance using the CIS benchmarks
Below I have tried to give an example of how Starboard can be used, especially in conjunction with other tools to support and ensure security of your clusters.
Installing Starboard is easy too, head on over to the project and simply choose from the installation options available.
Moving forward with the idea of integrating Starboard with OPA
I do remember @Liz Rice mentioning that they (OSS at AquaSec) were exploring OPA as an integration, so I thought I would show you a little bit about how that might work.
Ideally, we know that we need OPA to run as an admission controller (I’ll skip some of the basics of OPA because it’s been covered in great depth by other more experienced folks than I!). What we also know is that conceptually, we cannot run plain kube-mgmt to enforce policies ON the Custom Resource Definitions (hereon referred to as CRDs) that are provided. Rather, we would like to replicate the data produced by the CRDs in order to write policies enforceable on the data produced by the custom resources, which are;
CISKubeBenchReport
ConfigAuditReport
KubeHunterReport
Vulnerability
How can we achieve this?
It seems with relative ease! Kube-mgmt offer a way to sync all the CRD data into OPA for evaluation, where usually you would not have to do this to enforce policies on the input into the CRDs themselves, as described above. The process for syncing such resources is detailed here and has the following considerations;
- You will need to provide extra permissions to kube-mgmt to replicate the data for evaluation - this is something that you might not be comfortable doing, although shouldn’t hamper performance.
- Scanning earlier in the pipeline (build) is preferred, where you can fail build if developers are using outdated/vulnerable images with certain heuristics ( critical_vulns > 0, for instance).
- OPA is fail-open, so placing all your controls at the point of deployment (as mentioned above) should be discouraged.
I also followed the guide set out on the OPA website, which can be found here. This will take you through creating certificates (self-signed) for the admission controller and other associated steps before replicating the CRD data.
You will have to amend resources within the admission controller manifest, these are pointed out to you in the above links, however for brevity, see below for the changes/additions needed in order to get this to work (I didn’t think it was worth uploading to a separate git repo);
Add the new ClusterRole for your CRDs
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: crd-reader
rules:
- apiGroups: ["aquasecurity.github.io"]
resources: ["vulnerabilities", "kubehunterreports", "configauditreports", "ciskubebenchreports"]
verbs: ["get", "list", "watch"]
Add another ClusterRoleBinding
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: opa-crd-reader
roleRef:
kind: ClusterRole
name: crd-reader
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: Group
name: system:serviceaccounts:opa
apiGroup: rbac.authorization.k8s.io
To ensure replication of CRD data, add the arguments to the container spec for kube-mgmt
- "--replicate=aquasecurity.github.io/v1alpha1/vulnerabilities"
- "--replicate=aquasecurity.github.io/v1alpha1/kubehunterreports"
- "--replicate=aquasecurity.github.io/v1alpha1/configauditreports"
- "--replicate=aquasecurity.github.io/v1alpha1/ciskubebenchreports"
note: in order to find the resource version you can also just output one of the vulns resources you’ve run as yaml and | more
Everything should be ready to go!
For a specific Rego test case I was preparing, I could not find the image tag (:1.16) referenced within the CRD (kubectl get vulns <vuln resource> -o yaml), Aqua seems only to persist the left side of the “:”. This could have to been used to specify the minimum allowed version of an image. Perhaps this could be retrieved from the Deployment but given the nature of containers and allowing multiple version of the same software is not uncommon, this could be challenging.
The first port of call was to scan all Deployments in a namespace, consecutively. I couldn’t see an option to specify this so I made a small snippet below to just use xargs to pass in the output of kubectl get deployments -n dev -o wide to another starboard find vulnerabilities deployment/<placeholder> —namespace <placeholder> command to automate the scanning of deployments (I hope!).
kubectl get deployment -n <your namespace> | awk 'NR>1{print $1}' | xargs -I % sh -c 'echo %; starboard find vulnerabilities deployment/% -n <your namespace>'
Now for some Rego (prototyping)
I put this together fairly quickly, please do not judge my Rego too harshly, haha!
While I thought this might be a little easier to prototype, but the steps I took to mock up some Rego policies were of course to use the Rego Playground. I got some of the data from the CRDs by outputting it as JSON, then just loaded it into the input of the Playground. In practice, this might look a little different, you would have to import data.kubernetes.
But for the time being, this would suffice for our use case.
vulns.rego
package kubernetes.admission
import data.kubernetes.vulnerabilities
default allow = false
allow {
count(deny) == 0
}
deny[msg] {
image_match[image]
some i
get_vulns_summary[i]
i.criticalCount > 0
msg := sprintf("%v critical vuln(s) found for image: %v", [i.criticalCount, image])
}
##Helper rules below first is to extract the summary results, so we can filter for critical vulns
##In the deny rule
get_vulns_summary[tmp] {
tmp := vulnerabilities.items[_].items[_].report.summary
}
##Get the image that was scanned by Starboard (which resides in the label)
starboard_image[s_image]{
tmp := vulnerabilities.items[_].items[_].metadata.labels
s_image := tmp["starboard.container.name"]
}
##Get the image that was attempted to be deployed from the deployment object in admission
##Controller, this needs some work because I need to look at the format for admission review obj's.
requested_image[r_image] {
r_image := input.request.object.spec.template.spec.containers[_].image
}
##Returns image, if the images both match, and populate the image with the requested image
##Which will hopefully be denied
image_match[image] {
some i, k
s_image := starboard_image[i]
r_image := requested_image[k]
s_image == r_image
image := r_image
}
I left the comments in the policy for each step, but I have since made some changes to wrap some of the intended output into functions (boolean) which is waaaaaay easier to read (below). Overall, evidently it needs some love!
Assuming you have the admission controller installed, you can go ahead and create a ConfigMap with the name of your choosing, with the .rego file the above code is saved in passed in as an argument like so kubectl create configmap test —from-file=<yourfile>.rego -n <your namespace>
From what I have read, you can check the annotations of the ConfigMap in order to identify the status of the policy. See more here
The results? Pretty good!
The first final sample I ended up with was fairly straight forward in fairness and I’m certain that the code could be made more efficient (admittedly I am working on learning Rego). There was a bit of a nuance to designing policies with Starboard in mind, however, and I have given my observations below;
-
When stopping resources being deployed that haven’t been scanned, of course you needed to deploy the image to scan it with Starboard first (which wasn’t possible due to the rule). I thought I might be able to identify the time at which an image is scanned - which is included in the vulns resources - and create a warning when a deployment was created which hadn’t been scanned. I’m still figuring out a way I can block unscanned image in a reasonable way. A way around this would be to create a dedicated (dev) namespace with the appropriate isolation (netpol etc) to deploy images for scanning, then they can be promoted to appropriate namespaces after being scanned, subject to other policies. (See my sample workflow section below)
-
I believe every job pulled the Trivy Image, so I need to verify that it is not always being pulled when a new scan is kicked off (imagePullPolicy: Always?).
-
The image tag used in the spec is not persisted in the
"starboard.container.name"label, so controlling minimum allowed image versions is difficult.
A quick idea as to what a rejection (deny) from the policy will yield is below;

Functions
I rather sketched some skeleton functions that I will try to build out, rather than supplying the full thing, I’m still new to OPA and Rego, so I did reach out to the OPA Slack and got some great help (thanks and credits to @Ash Narkar!!!);
package kubernetes.admission
#import data.kubernetes.vulnerabilities
default allow = false
violation[{"msg": msg}] {
msg := get_unsafe_images(image_match, crit_count_by_image)
}
violation[{"msg": msg}] {
count(image_match) > 0
msg := get_unsafe_images(image_match, crit_count_by_image)
}
allow {
get_safe_images(image_match, crit_count_by_image)
}
get_unsafe_images(image_match, crit_count_by_image) = msg {
input_container[i]
count(image_match) == 0
msg := sprintf("Container %v forbidden, no image scan records found", [i])
}
get_unsafe_images(image_match, crit_count_by_image) = msg {
image_match[d]
crit_count_by_image[i]
d == i
crit_count_by_image[i] > 0
msg := sprintf("Container %v forbidden, critical vulnerabilities identified in image", [i])
}
get_safe_images(image_match, crit_count_by_image) = msg {
image_match[d]
crit_count_by_image[i]
d == i
crit_count_by_image[i] < 1
msg := sprintf("Container %v allowed, no critical vulnerabilities identified in image", [i])
}
##Helper rules are below
input_container[c] {
#Will be changed input.request.object.spec.containers[_]
c := {"busybox"}
}
##Should be rule to extract the necessary fields from data.kubernetes.vulnerabilities
vulnerabilities := input
##New rule to match images to their respective criticalCount
crit_count_by_image[image] = cCount {
item := input.items[_].items[_]
image := item.metadata.labels["starboard.container.name"]
cCount := item.report.summary["criticalCount"]
}
##Find matches to images in the vulnerability reports with the requested image
image_match[a] {
item := input.items[_].items[_]
a := item.metadata.labels["starboard.container.name"]
input_container[c]
c[a]
}
Please forgive the arbitrary variable names, I was in a rush ;)
One good use case that could be coded into a policy is to iterate over the vulnerabilities for certain CVE’s. As well as using the vulnerabilities CRD to create your policies, you can use the other resources to build out the security around your cluster.
A quick sample workflow as a closing thought (draw.io has k8s objects! :o )
Allowing people to scan their own images, and having something (job etc) to automate the PUT .. /v1/data part could also be a nice workaround, in very small development setups.
This of course introduces a new set of challenges, such as which people should be able to submit data into OPA to be evaluated, as you want to keep this data as clean as possible, and not overload where necessary. Things that you can consider from a security perspective also include watching the audit.k8s.io/v1beta1 response for people labelling namespaces with the opa/ignore tag, which excludes them from being evaluated by any policies you’ve pushed to OPA!
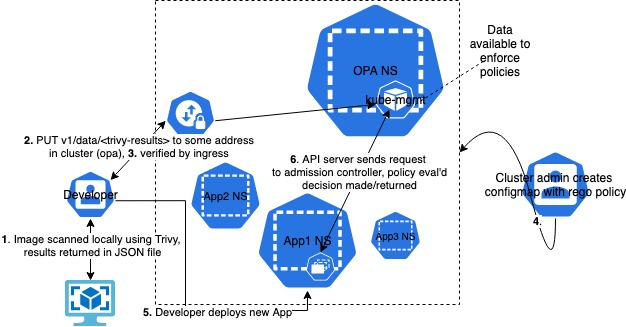
As you can see, I need to work on my diagramming skills too ;) thanks for reading! I’ve decided in my next post I’ll get down in the weeds of TypeScript with a new AWS project “cdk8s” :)